Segnalo questa serie di articoli scritti da Silvio che spiegano come aggirare i captcha, ovvero i fastidiosi test somministrati da una macchina ad un umano per sapere se il “testato” è una macchina o un umano (un test di Turing al contrario?).
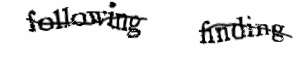
In sintesi, il processo è diviso in più attività:
- la riduzione del rumore di fondo;
- l’identificazione del contorno dei caratteri, la loro segmentazione (sono rimasto affascinato dall’algoritmo di flood filling) e la normalizzazione;
- ed infine la parte più interessante: il riconoscimento dei caratteri tramite algoritmi OCR basati sulle reti neurali.
La spiegazione di Silvio è molto accurata e semplice, e indica numerosi ed interessanti riferimenti per l’approfondimento, oltre ai link dei programmi utilizzati (rigorosamente opensource). Da leggere!
“Meno male che Silvio c’èèèè” :D